
During the first semester in my studies of Cognitive Science at the University of Vienna, I had the good fortune of taking the class Capabilities and Limitations of Language-Based Artificial Intelligence with professor Benjamin Roth. In this class we discussed a plethora of literature that underlined the modern state of large language models and natural language processing. The format of the course went as follows. Each student selected three papers they were mostly interested in from a list curated by the professor after which they were assigned a paper to make a roughly 30 minute presentation about, and then at the end of the course write a 15-20 page report about putting the research into a wider context. I chose the papers Bender et al. (2021) On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜, Bolukbasi et al. (2016) Man is to Computer Programmer as Woman is to Homemaker?, Searle (1980) Minds, brains, and programs, Devlin et al. "Bert: Pre-training of deep bidirectional transformers for language understanding.", and Schick et al. (2023) Toolformer: Language Models Can Teach Themselves to Use Tools and the paper I got assigned was BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. While at the time I was not too stoked on this decision, later, when writing the report, I found it to have been an incredible turn of events, as BERT provided the foundation for a lot of LLM research and I had already read a lot of it. In this blogpost I want to have a brief rundown of my presentation and paper, and provide you guys with a hopefully comprehensive understanding of why BERT is an awesome language model.

Here is the structure the presentation took on.
The background research and motivation for BERT was quite simple. Since the release of Attention is All You Need by Vaswani et al. transformer models took over the field of natural language processing reaching incredible performance abilities with models like ELMo and GPT reaching the state-of-the-art. Before BERT models were either Feature-based lioke ELMo where the models were pre-trained on a specific task, or fine-tuned like in the case of OpenAI’s GPT where there is minimal task specific architecture and a fine-tuning phase follows the pre-training of the model in order to increase performance on said task. The researchers of BERT wanted to concatenate both of these methods while also improving the self-attention mechanism of the transformer model.
This created BERT
The data BERT was trained on was BooksCorpus and the English Wikipedia. BooksCorpus is a collection of books from unpublished authors on the internet. The English Wikipedia was stripped of all of lists, tables, and headers, as to not throw off the formatting of the dataset. An essential aspect of the dataset was that it could not have been shuffled as BERT encoded the meaning within sentences as well as between sentences.
The architecture of the model was the standard transformer architecture outlined in Attention is All You Need with the twist of having bidirectional self-attention. The mechanism will be demonstrated in a further slide but simply put the model encoded context from both before and after the predicted token.

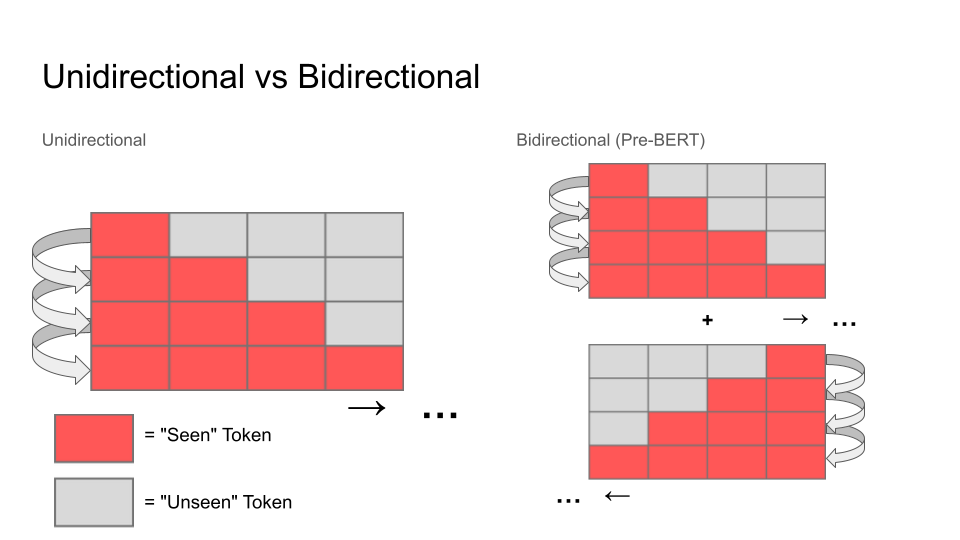
Unidirectional attention is the common generative model self attention mechanism where all tokens are revealed to a model sequentially one at a time with the context for each token to be predicted being defined by all of the tokens that came before it. In this diagram the red boxed are the seen tokens which the models predicted and that inform the meaning of the next token. The grey boxes represent the “yet to be seen by the model” tokens which do not inform the context of the current token. While models such as ELMo were technically bidirectional, they utilised a shallow concatenation of two models, one trained with left-to-right attention and the other trained with right-to-left attention as seen on the diagram on the right.

BERT achieved true deep bidirectional attention by implementing the Cloze task as the self-attention mechanism. This means that instead of revealing the tokens to the model sequentially, it hid or masked-out a portion of the dataset, which was to be predicted all at once (of course in batches but that is besides the point). This allowed the context of each guessed token to be informed by the tokens on each side of it without revealing the answer to the model as is the case with a LTR+RLT model.
For the pre-training tasks BERT implemented two strategies: the masked language modeling task (MLM) and the next sentence prediction task (NSP). It did this in a clever way that allowed for great generalisability in fine tuning down the line.
BERT can encode both single sentences and sentence pairs, and capture the relationships between the sentences using a general label. This allows for BERT to not only have a task-general architecture, but also to be fine-tuned using the same architecture as the pre-training, greatly simplifying the fine tuning process. This design decision also made BERT valueable for the open-source community as it allowd for compute-inexpensive and accessible fine tuning.
This is how BERT implemented the Cloze task. The tokenizer uses special tokens like [MASK], [SEP], and [CLS] in order todeliniate the sentences and the to-be-predicted-words. 15% of the whole dataset is masked out and replaced with either the [MASK] token, a random word, or the correct word in order to train the model and bias it towards the correct word decision at the end. This simple yet robust architecture is what allowed for the true deep bidirectionality of the model.

The next task BERT was trained on was NSP or next sentence prediction. This task allowed BERT to encode meaning not only within sentences but also between sentences. This architecture also allowed for the generalisation of tasks allowing the fine tuning of the model to be quite flexible. This was done by ordering and labeling the sentences and categorically defining the relationship between them and assigning said relationship to a label. This can be done with any numberical or categorical data and improves the models performance on tasks such as question answering and natural language inference. In the task itself 50% of sentences were shuffled and in 50% the order was maintained to train the model.
Again since the architecture is so general, it is possible to fine tune BERT with many different kinds of datasets allowing for a simple and yet robust model utilisation.
Here is an example I had the class classify, see if you can solve it for yourself :D
The results that BERT was able to achieve were groundbreaking. The model was able to outperform all previous state-of-the-art models on all evaluated tasks. This is something that even OpenAI's GPT was not able to achieve. This marked a big step in the improvement of language models and inspired much of the innovation we see today in this field. BERT was evaluated on GLUE, SQuAD, and SWAG and even outperformed humans on some of the evaluated tasks.
The BERT team also conducted ablation studies (or studies where they tested performance after taking out specific parts of the architecture) and discovered that all of the architectural aspects of BERT contribute to its good performance. This was later analyzed again and it was found in RoBERTa that the NSP task does not contribute to the performance that much, and thus it was taken out in later models.
So what are the takeaways of this consequential paper? For one it showed that architecture matters, and that it matters a lot. Performance, as it is evaluated by current tests, will be most impacted by the fundamental architecture of the models. This architecture is what allows for better performance, as dataset curation and size can only take you so far when making new models. Another big thing that BERT showed is that increasing dataset size leads to increasing performance. This caused the race for increasing model size, the effects of which can still be felt today.
If you are further interested in this topic, I also wrote a comprehensive analysis of the BERT model and its implications for machine learning which can be found below!





















Komentáre
Zverejnenie komentára